About the Project
Traditional teaching practice evaluation relies on direct human observation, an approach that is expensive, logistically complex, and inherently subjective. MoviSound addresses this gap by processing synchronous classroom recordings through a multimodal AI pipeline and delivering structured, explainable feedback to teachers through a web interface.
The platform was developed as a decoupled microservices architecture (Python, FastAPI, Docker, Celery) combining end-to-end audio analysis (ASR via Whisper, speaker diarization, paralinguistic feature extraction) with fine-tuned language models (BERT) interpreted through SHAP-based explainability frameworks. The goal is not just classification accuracy, but transparency: teachers need to understand why the system draws the conclusions it does.
This platform is the applied result of my doctoral thesis, awarded Summa Cum Laude by the University of Murcia in 2026.
System Architecture
Each node in the diagram represents an independent Docker container. The pipeline ingests classroom recordings, processes them through audio analysis and transcription stages, applies multimodal fusion, and exposes results through a REST API consumed by the web frontend.
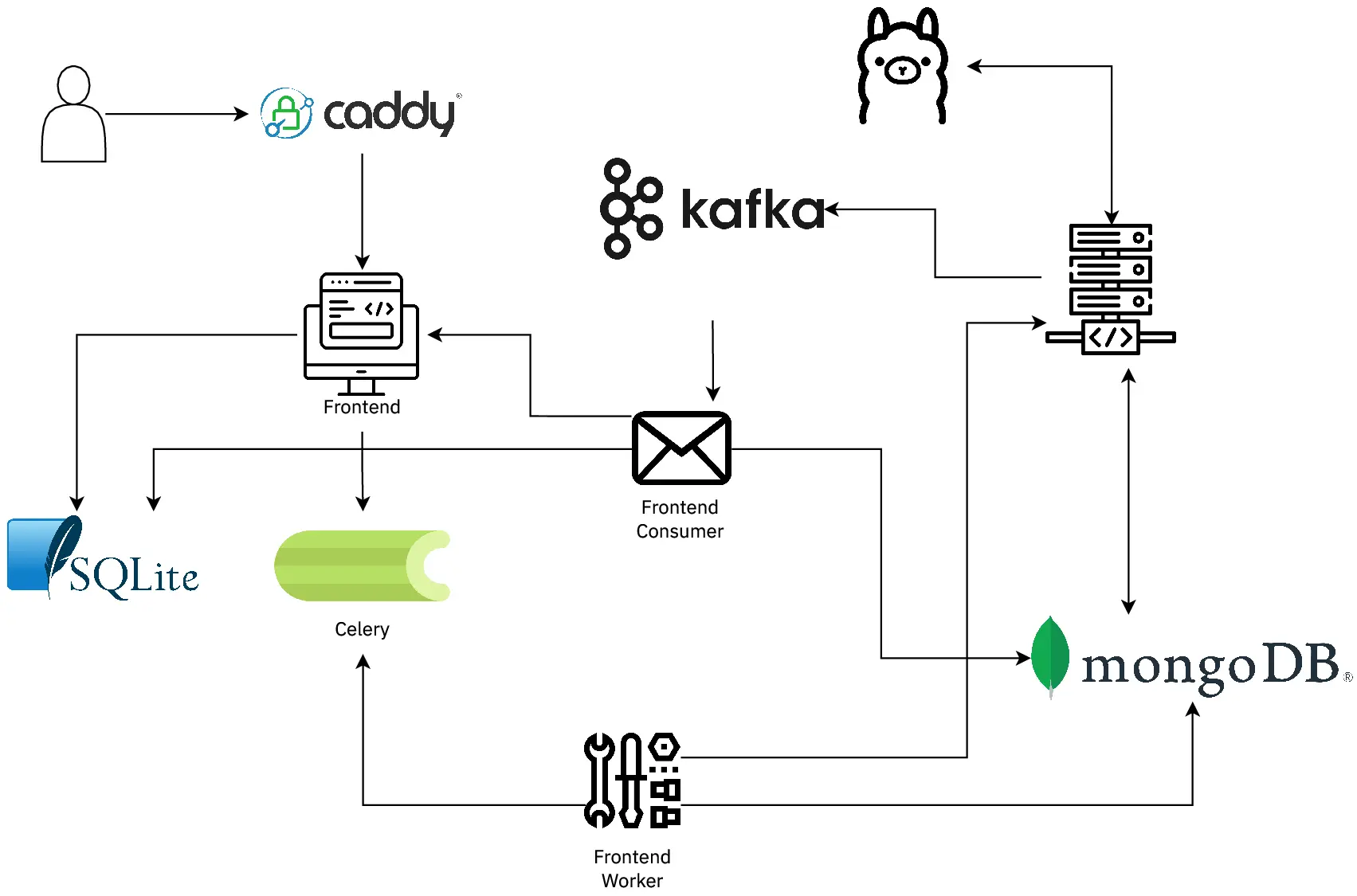
MoviSound microservices architecture
Platform Demo
The following recording shows the MoviSound web interface processing a real classroom session and visualizing the extracted metrics. A full walkthrough with narration is coming soon.
Research Publications
The platform was developed across three peer-reviewed papers published in JCR-indexed journals, each covering an incremental phase of the methodology.